How we built the SOTA browser agent that outperforms Fable

Aside achieved the highest score on multiple agentic browsing benchmarks. The internet did not believe us and said our claim was based on 'trust me bro'.
Fair. Honestly, we didn't believe it at first either. Trust me, we spent more time verifying our results than running the benchmark.
But this isn't luck. We built the agent harness from scratch, tightly engineered around our own principles. In this post, we're sharing exactly how we did it.
What is Aside?
Aside is a browser built to do real work across the websites you already use.
I love browsers, but I was disappointed by Dia, Perplexity Comet, and ChatGPT Atlas. Their agents felt too dumb to finish even one real task.
So we built a real AI browser from the ground up:
- It uses your logged-in accounts directly, the same way you do. No integrations, no API glue.
- It remembers your work with self-organizing memory, powered by local embedding models.
- Credentials are autofilled into pages without ever being exposed to the model. Sensitive actions wait for your approval.
- It is a real browser, so it does not get detected as a bot.
Benchmark results
We ranked #1 on three browser agent benchmarks: Online-Mind2Web, BU-Bench-V1, and Odyssey.
Online-Mind2Web
The most widely reported browser agent benchmark. 300 real-world tasks across 136 live websites, covering various consumer workflows. It's the one every web agent gets compared on.
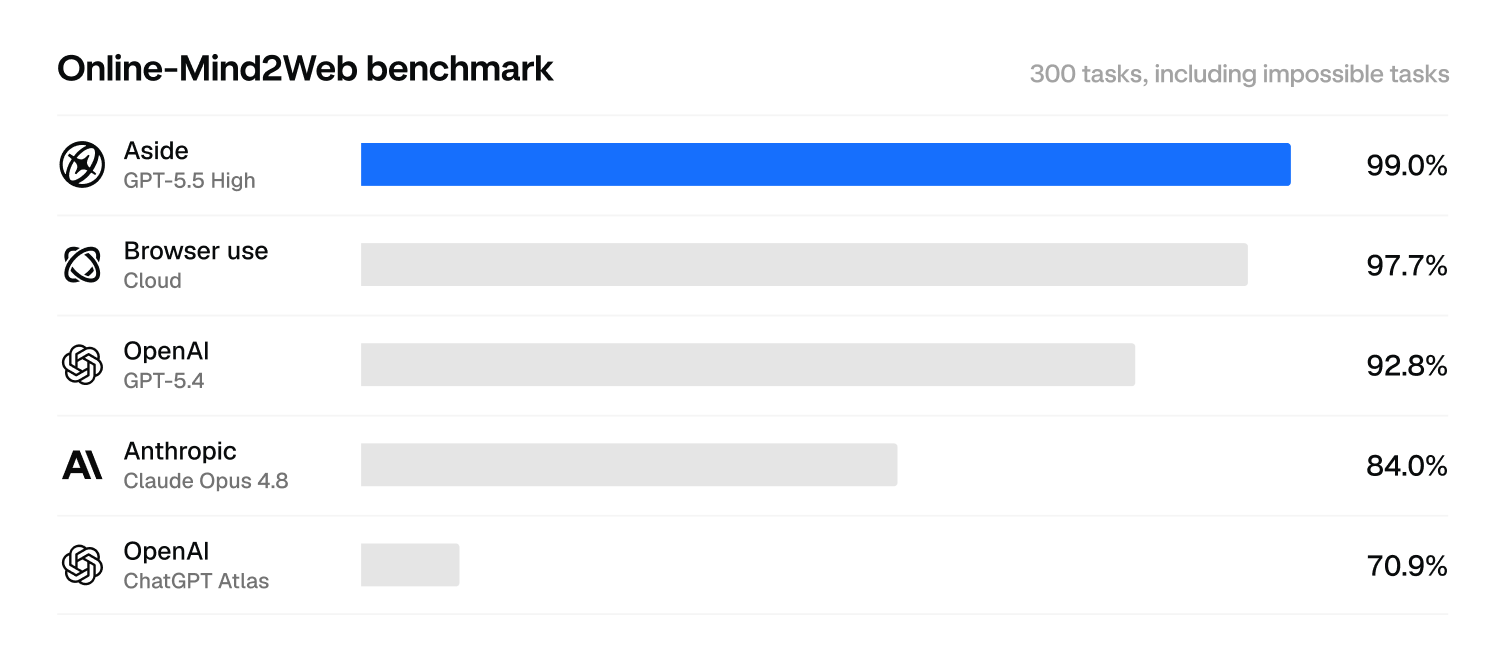
Aside + GPT 5.5 99.0%. GPT-5.4 with CUA is at 92.8%, Opus 4.8 + Claude Code (Playwright MCP) at 84.0% (in our run), and ChatGPT Atlas at 70.0%.
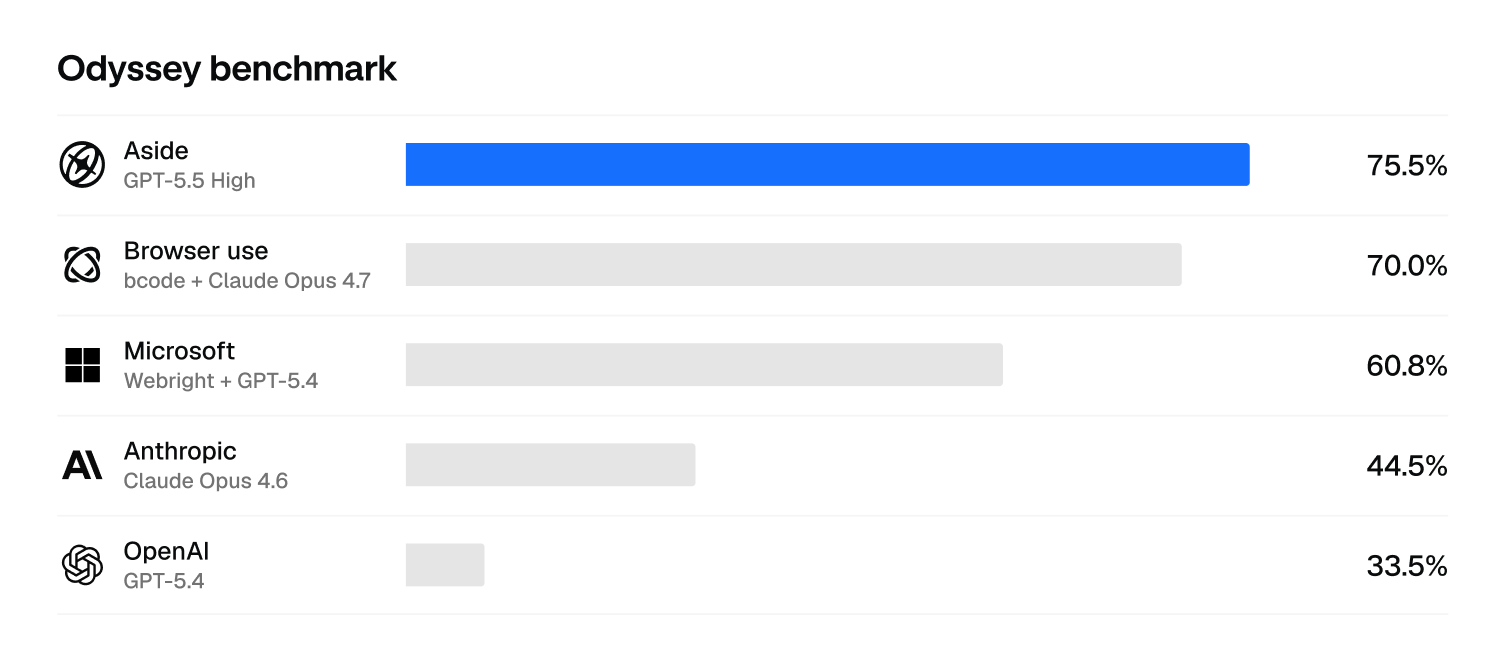
Odyssey
Odyssey is CMU's long-horizon benchmark. 200 multi-site tasks derived from real user browsing histories, like "plan a trip to all 30 MLB stadiums" or "compare a Tesla Model 3 lease in LA against trailer alternatives under $10K."
BU-Bench-V1
Browser Use's open benchmark. 100 hand-selected hard tasks pulled from WebBench, Mind2Web 2, GAIA, and BrowseComp.
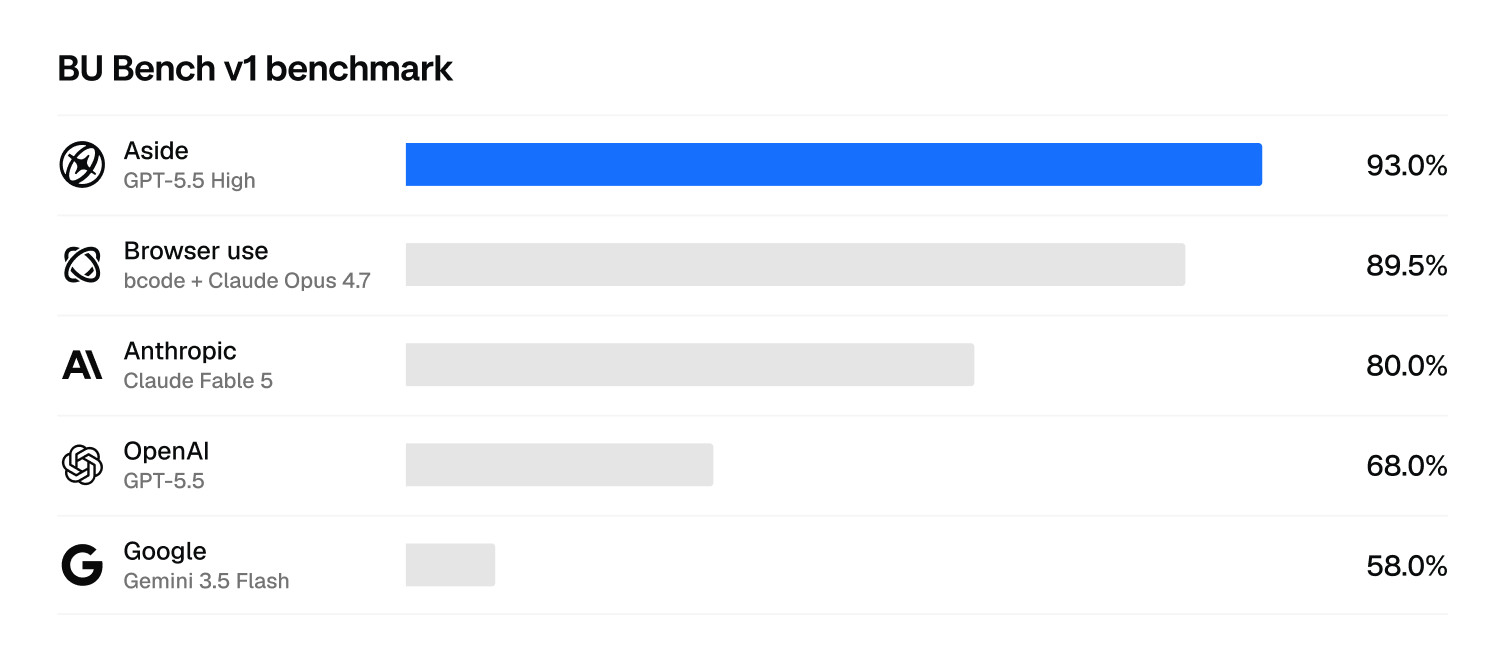
Aside + GPT 5.5 hit 93.0%. Fable 5 + Claude Code (Playwright MCP) scored 80% in our run, while Fable 5 + Browser Use OSS also scored 80%.
Fun side note: Aside + Kimi K2.6 even beats Fable 5 + Claude Code.
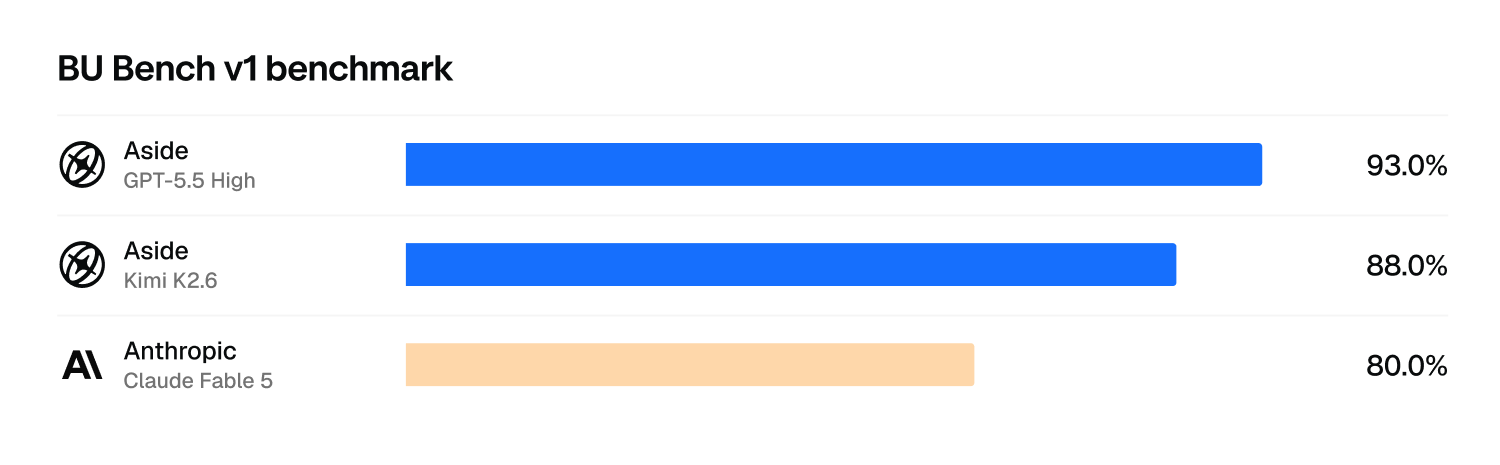
But isn’t it nonsense to compare models against your harness?
You’re right, and sorry for the ragebait. But I’m not talking about the model’s efficiency. I’m talking about the efficiency of the harness.
Harness matters a lot. The model still drives the ceiling, but there is a lot you can optimize by building a better agent harness.
How we built the most intelligent browser harness
We built most of our harness from scratch.
We chose pi-mono/core as the foundation, but we had to build everything else on top of it ourselves (e.g. compaction, skills, hooks, sandbox, REPL, bash, and browser automations), because we had our own principles we wanted to stick to.
Principles
1. Follow the model’s training data.
Aside is a coding agent. Yes, you heard that right. When I first designed Aside, I asked myself: what data have LLMs seen the most? Code.
When I started ML research in 2016, my core belief was simple: all ML models are just statistical nonlinear functions. So if you're not building frontier models yourself, your best bet is to follow their training data distribution.
That’s why our core tool is a JS REPL, built on Playwright's syntax since it's the most widely used.
2. Minimal instruction leads to more intelligence.
We found that hallucinations and dumb behavior mostly come from two things: a poor description of the current state, and conflicting instructions.
So we keep our system prompt tight. Ours, including tool definitions, costs 10K tokens. Claude Code burns 20K.
We also never let AI write prompts. It just piles slop on slop. Running autoresearch on benchmarks produces a flood of benchmaxxing rules like “When X, do Y” or “Never do A, B, C.”
3. Protect the context window
Useless tokens in the context window are the root of all evil. When tool outputs are full of noise (e.g., a DOM capture where divs and styles make up 90% of the content) or instructions are bloated with irrelevant details, the model degrades fast.
A good harness keeps tool outputs high-signal and low-noise. For instance, CDP or raw DOM is a poor choice for browser control. The protocol is far too raw for a model to parse effectively. That is why we use a customized a11y tree instead.
4. Stand on the shoulders of giants.
We did not invent everything from scratch. We borrowed from great open source projects: Codex, Claude Code, OpenCode, oh-my-opencode, and more.
Aside is a coding agent.
Aside is basically a coding agent. We have only two core tools: REPL and bash. Aside writes Playwright JS code to control browsers, unlike OpenClaw or Hermes, which use dedicated browser-control toolsets.
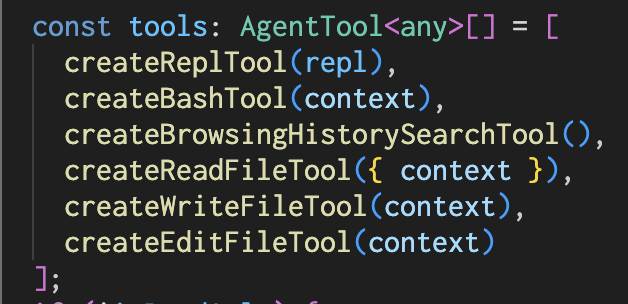
Why a JS REPL? Because it sits close to the model’s training data, and code is the clearest way to express logic and data. That matters in real tasks. Aside can fill complex forms and inspect a YouTube video frame by frame because the agent can write code.
Sometimes, Aside reverse-engineers the site’s API. If the page blocks the normal path, it captures network requests, figures out the internal API, and uses that as a workaround. The request looks identical to the site’s own request, so it does not get flagged as a bot. I like this because making Aside closer to a coding agent created these smart side effects.
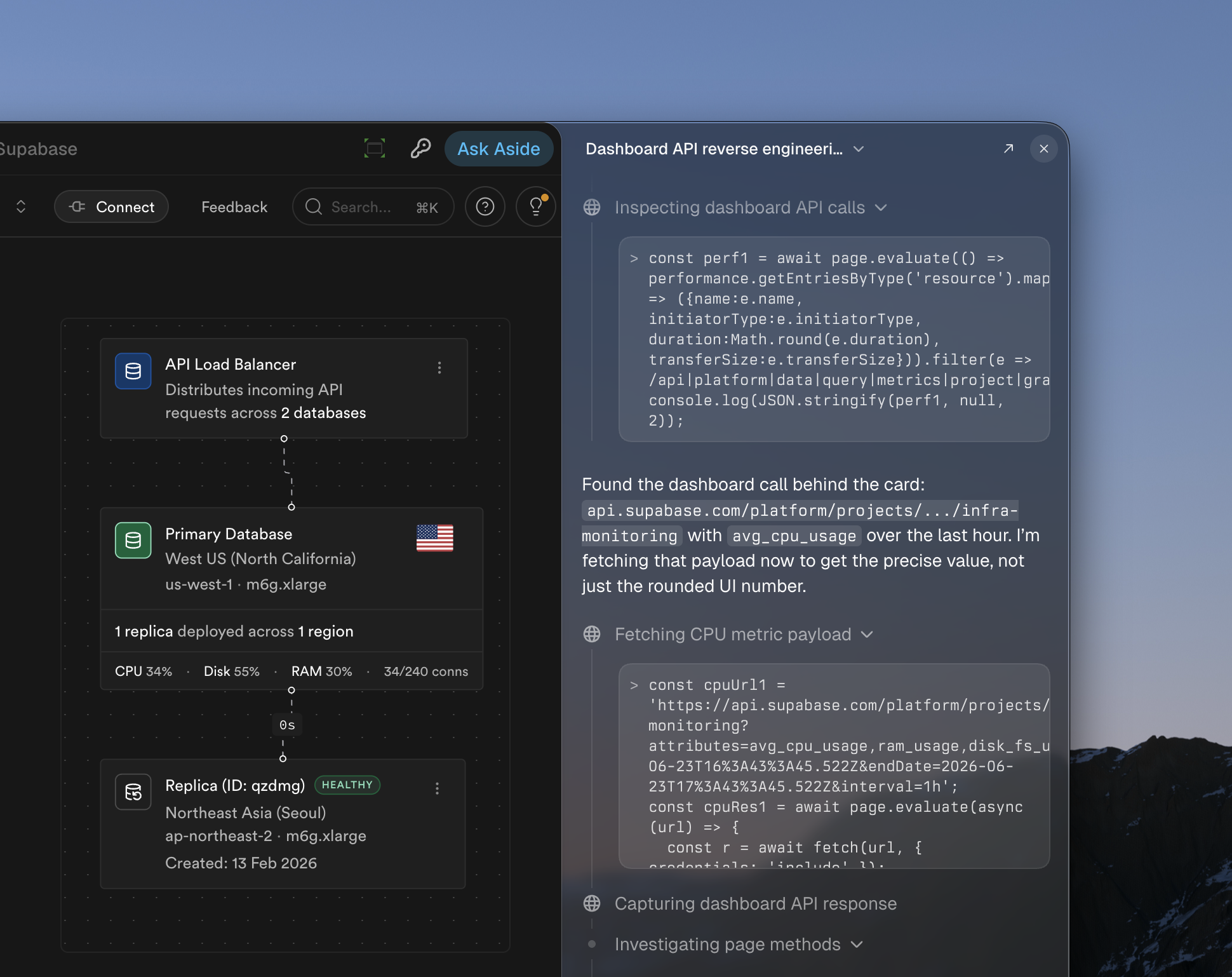
Playwright is the browser language LLMs already know
Why Playwright? Because it is the browser automation API LLMs have seen the most. OpenAI even said GPT-5.4 was trained to use Playwright well. My first reaction was simple: if the model already knows this interface, why invent a new one?
The wild part is that our prompt does not teach Playwright. Playwright MCP spends 13K tokens explaining it. We just say, “Playwright is available.” Aside still performs better because we save tokens and avoid extra instructions.
Side note: CDP is a bad idea
Recently, we saw a trend of using CDP for browser control. We think it is usually a bad idea (sorry, Browser Harness). It looks great from an engineer’s point of view: one interface for everything. But the problem is simple:
- LLMs are not trained to use CDP
- CDP is a low-level debugger protocol
- It wastes tokens, and LLMs have a hard time using it
As I said before, it is better not to fight the LLM’s training data distribution. The key is to choose the right abstraction, one the model already understands.
Playwright → Asidewright
But Playwright is bloated and heavy because it’s designed for E2E test automation, not for agents. So we made our own: Asidewright.
- Familiar to LLMs: interface is 100% identical to Playwright
- Lightweight: Each API is an opinionated, thin wrapper around CDP methods. No injected scripts, middle layers, or bloat.
- Token-efficient: up to 80% fewer tokens than agent-browser
- Agent signals: reports asynchronous events to the agent with steering messages, such as popup opened, download started, and tab closed.
Token-efficient a11y snapshots
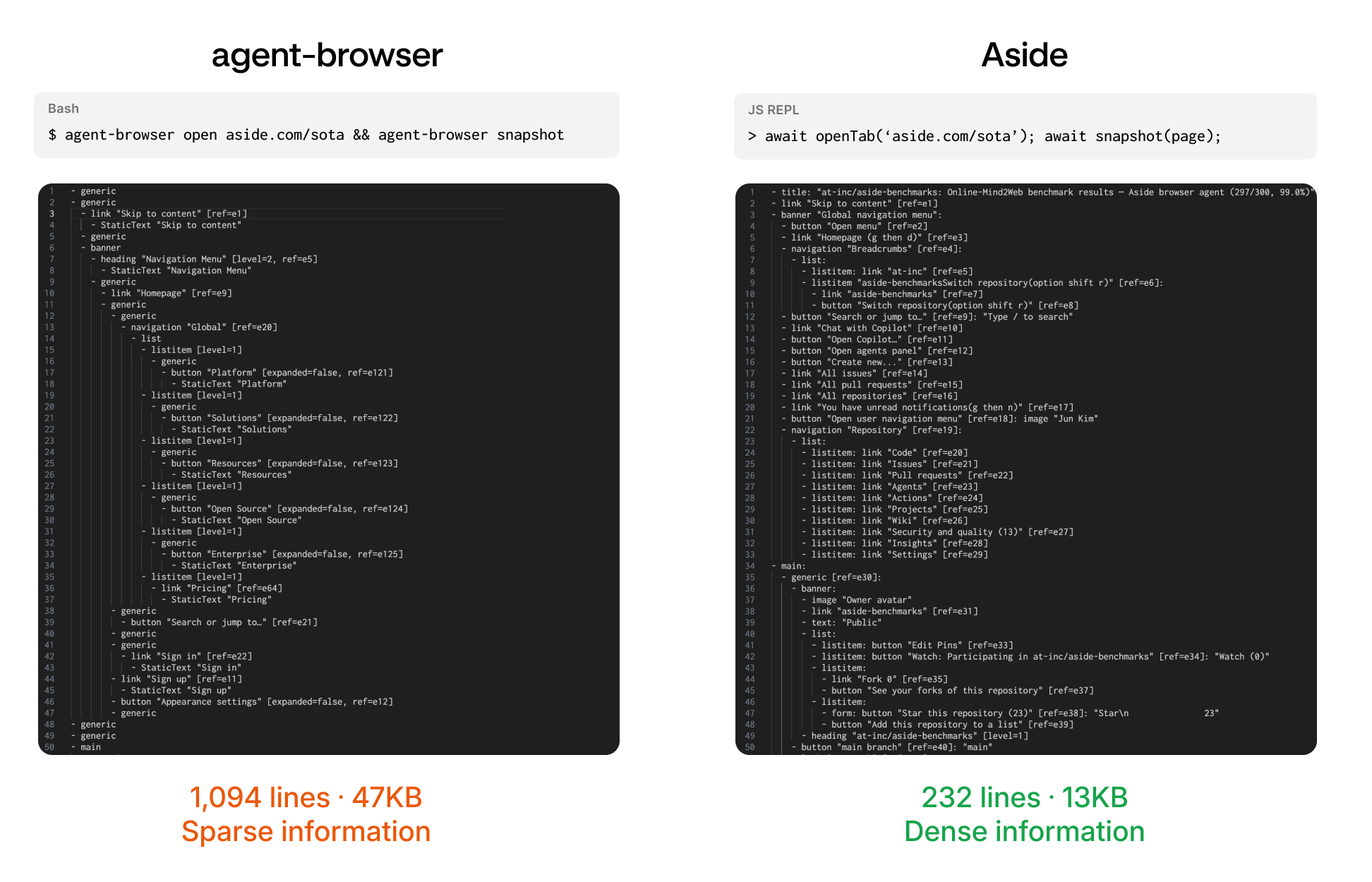
The recent norm for web interaction is the accessibility tree. Claude, agent-browser, Playwright MCP, and OpenClaw all use an accessibility tree with ref IDs for interactive elements.
We built our own modified accessibility tree. We remove many intermediate elements with heuristics and add information that helps LLMs, such as focus state, iframe ID, and clickable state.
After snapshotting aside.com/sota and comparing it to agent-browser, Aside's output was 70% smaller with key information packed upfront. This means agents are far less likely to miss critical details when tool results get truncated.
Fallback: Computer Use with screenshots
Of course, some websites cannot be controlled through the DOM. We added a CUA interface to Asidewright so Aside can use visuals and click coordinates when needed.
Tech details that make it work in a real user browser
Building a headless browsing agent is very different from building one that lives inside a real user's browser.
Tabs open in the background. Chrome-extension-based AI agents steal the user’s focus every time. We patched Chromium’s Blink engine so tabs opened by the agent do not take focus, open popups, or interrupt the user’s foreground task.
Avoiding bot detection. We modified Chromium internals using the same technique used by Browserbase and Browser Use.
Viewport locked at 1440x900. If you have used Codex Browser, you have seen the chaos: the browser window shifts every time you resize your screen, and every action breaks.
We patched Blink so background tabs opened by the agent always render at 1440x900, regardless of the user’s window size.
Bonus: most Computer Use training data is around this resolution, so CUA models behave much better here. Remember the first principle: follow the model’s training data.
Conclusion
The claim that Aside beat Fable is honestly a bit of ragebait. But over the last four months in stealth, we built a SOTA agent with top-tier performance. It came from experiments, research, and a lot of careful engineering.
We care this much because Aside is an agent that uses websites as tools to do ordinary work for users. Real-world work is often messier than coding. That makes a well-built harness much more important for general agents than people think.
FAQ
- Q. Will you release the browser framework? If people want it, yes.
- Q. Will you open-source the browser? No.
Curious? Download Aside now.